
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- customeoperator
- 감성분석
- GoEmotions
- LDA
- featureimportance
- 티스토리챌린지
- 데이터분석
- pythonlearner
- 텍스트마이닝
- 래피드마이너
- 데이터크롤링
- 머신러닝
- 오블완
- agglomerative clustering
- 통계개념
- nrcemotionlexicon
- datacrawling
- causalanalysis
- 데이터
- 토픽모델링
- htmltags
- sentimentanalysis
- 파이썬러너
- 올라마
- 인과분석
- llma
- 커스텀오퍼레이터
- RapidMiner
- 채용공고분석
- customoperator
Archives
- Today
- Total
마이와 텍스트마이닝
파이썬을 활용한 데이터셋의 기초 통계 개념 본문
데이터에 대한 이해를 높이기 위해 통계 함수와 그 분석은 매우 중요한 역할을 합니다. 또한 머신러닝 알고리즘에서도 필수적으로 사용되며, 중요한 기반이 됩니다. 이번 글에서는 파이썬을 이용해 기본적인 통계 기법들을 살펴보겠습니다. 이러한 기법들은 EDA(탐색적 데이터 분석) 과정에서도 자주 활용됩니다.
먼저 데이터를 불러오겠습니다. Kaggle에서 다운로드한 customer churn 데이터입니다.
https://www.kaggle.com/datasets/muhammadshahidazeem/customer-churn-dataset
Customer Churn Dataset
Predict Customer's Retention
www.kaggle.com
import pandas as pd
import numpy as np
import math
import statistics
import matplotlib
import seaborn as sns
from scipy.stats import gmeandf = pd.read_csv("customer_churn_dataset-testing-master.csv")df.head()

- Mean (평균)
데이터 값들의 합을 데이터 개수로 나눈 값입니다.
# Mean
df.mean(numeric_only=True)CustomerID 32187.500000
Age 41.970982
Tenure 31.994827
Usage Frequency 15.080234
Support Calls 5.400690
Payment Delay 17.133952
Total Spend 541.023379
Last Interaction 15.498850
Churn 0.473685
dtype: float64
- Geometric Mean (기하 평균)
모든 데이터 값을 곱한 후, 데이터 개수만큼 루트를 씌운 값입니다.
# Geometric Mean
gmean(df["Age"])39.44058305604248- Harmonic Mean (조화 평균)
데이터 값들의 역수 평균을 구한 후, 그 값을 다시 역수로 변환한 값입니다.
# Harmonic Mean
statistics.harmonic_mean(df["Age"])36.78006899556641- Mod (최빈값)
데이터 중 가장 많이 나타난 값을 의미합니다.
# Mode
df[["Tenure"]].mode()- Median (중앙값)
데이터를 크기순으로 정렬했을 때, 중앙에 위치한 값을 의미합니다.
# Median
df["Age"].median()42.0- Variance (분산)
데이터 값들이 평균으로부터 얼마나 퍼져 있는지를 나타내는 지표입니다.
# Variance
statistics.variance(df["Usage Frequency"])77.73014447155514OR
df["Usage Frequency"].var()77.73014447155514- Standard Deviation (표준편차)
분산의 제곱근으로, 데이터의 흩어짐 정도를 나타냅니다.
# Std Dev
statistics.stdev(df["Payment Delay"])8.852211096659286- Normal Distribution (정규 분포)
데이터가 평균을 중심으로 좌우 대칭 형태를 이루는 종 모양의 분포입니다.
# Dist Plot
sns.distplot(df["Age"], hist=True, kde=True)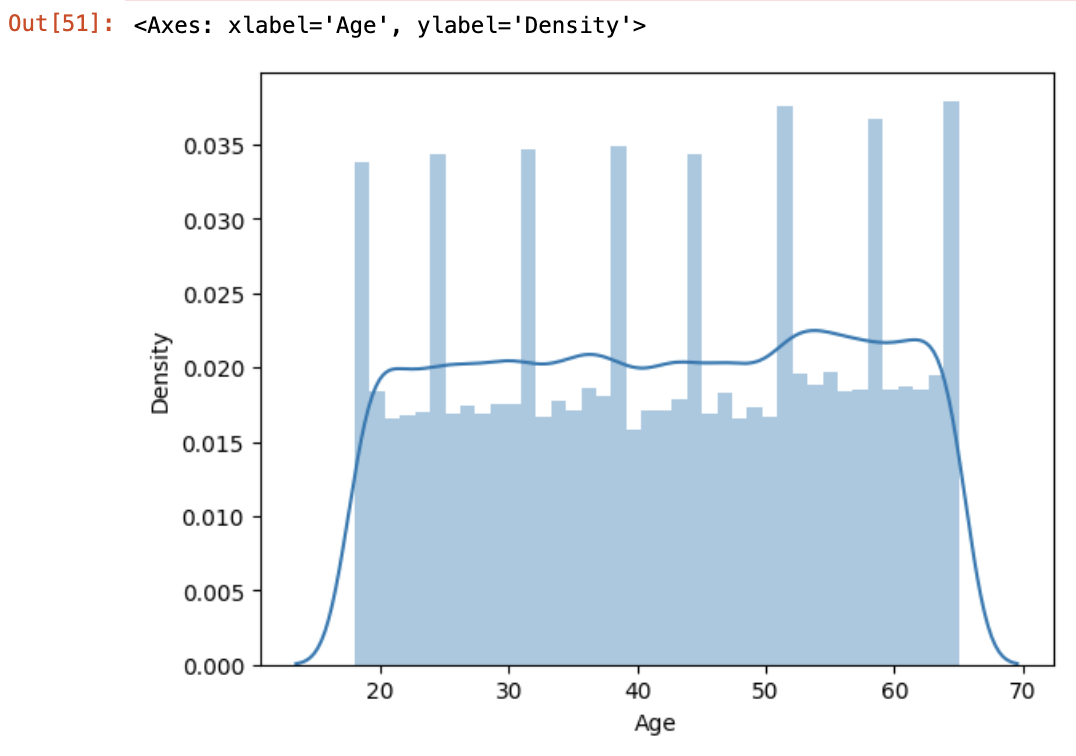
- Skewness (왜도)
데이터 분포의 비대칭 정도를 나타내는 값입니다.
# Skewness
df.skew(numeric_only=True)CustomerID 0.000000
Age -0.040894
Tenure -0.126056
Usage Frequency 0.037543
Support Calls -0.192854
Payment Delay -0.350714
Total Spend 0.047746
Last Interaction 0.005112
Churn 0.105408
dtype: float64
이 글에서는 파이썬을 활용한 데이터셋의 기초 통계 개념을 다뤄보았습니다. 앞으로 남은 통계 방법들에 대해서는 다음 글에서 더 자세히 설명드리겠습니다.