
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- LDA
- 오블완
- 올라마
- 티스토리챌린지
- 텍스트마이닝
- 래피드마이너
- llma
- customoperator
- 채용공고분석
- 머신러닝
- 통계개념
- featureimportance
- agglomerative clustering
- 인과분석
- 데이터분석
- customeoperator
- RapidMiner
- 데이터크롤링
- 토픽모델링
- datacrawling
- GoEmotions
- 커스텀오퍼레이터
- nrcemotionlexicon
- pythonlearner
- 파이썬러너
- sentimentanalysis
- 데이터
- causalanalysis
- htmltags
- 감성분석
- Today
- Total
마이와 텍스트마이닝
래피드마이너에서 파이썬 러너를 활용한 머신러닝 알고리즘 커스텀 오퍼레이터 만들기 본문
안녕하세요,
이번 블로그에서는 RapidMiner에서 Python Learner를 사용하여 원하는 모델의 커스텀 오퍼레이터를 만드는 방법에 대해 알려드리겠습니다.
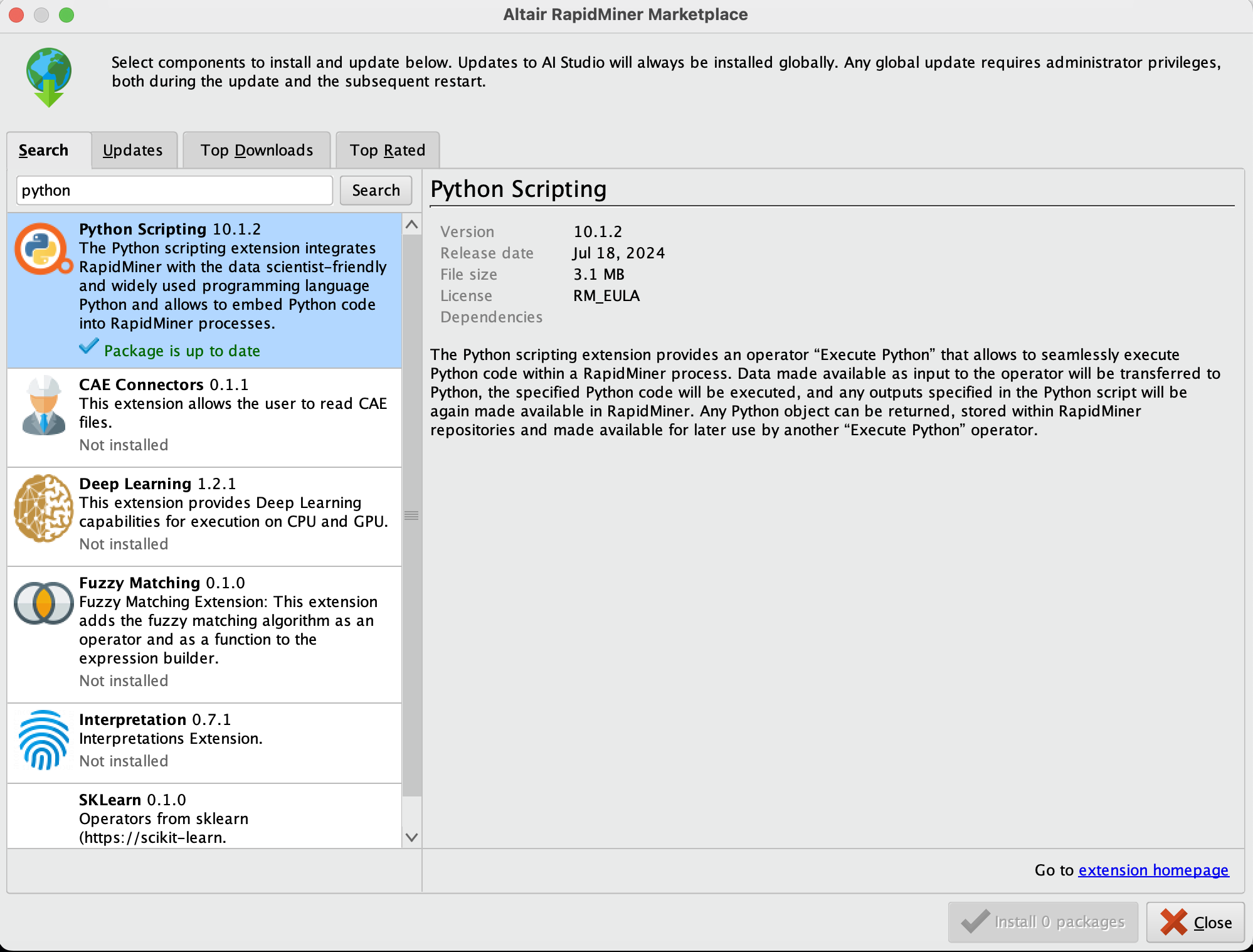
다운로드 후에, 오퍼레이터 창에서 이제 파이썬 관련 오퍼레이터들을 확인할 수 있습니다. 우리가 만들 모델 머신러닝 모델 오퍼레이터이기 때문에, Python Learner 오퍼레이터를 선택해야 합니다.
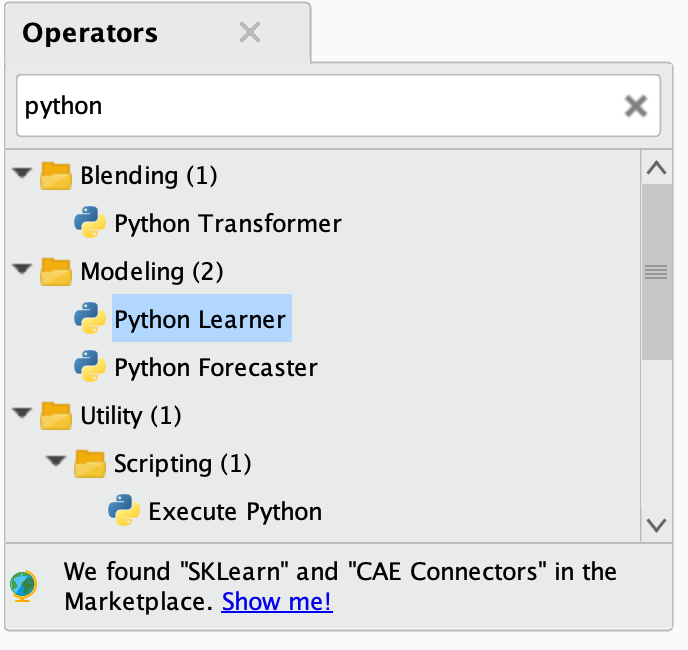
오늘 만들 오퍼레이터는 LightGBM 모델 오퍼레이터입니다. 이 LightGBM 오퍼레이터를 만드는 주된 목적은, 이후에 다양한 데이터셋에 대해 반복해서 사용할 수 있도록 하는 것입니다. 즉, 데이터를 매번 수동으로 전처리하고 모델에 맞추는 작업을 생략하고, 이 오퍼레이터를 사용하여 데이터를 자동으로 학습시키고, 예측을 할 수 있게 됩니다.
우선 우리가 만들 오퍼레이터가 제대로 작동하는지 확인하기 위해 데이터셋이 필요합니다. 데이터셋은 Kaggle의 Breast Cancer 데이터를 사용하였습니다. 이 데이터셋은 유방암 환자에 대한 여러 가지 특성을 포함하고 있으며, 이를 통해 유방암의 진단과 예측을 위한 머신러닝 모델을 학습하는 데 활용할 수 있습니다.
프로세스 시작:
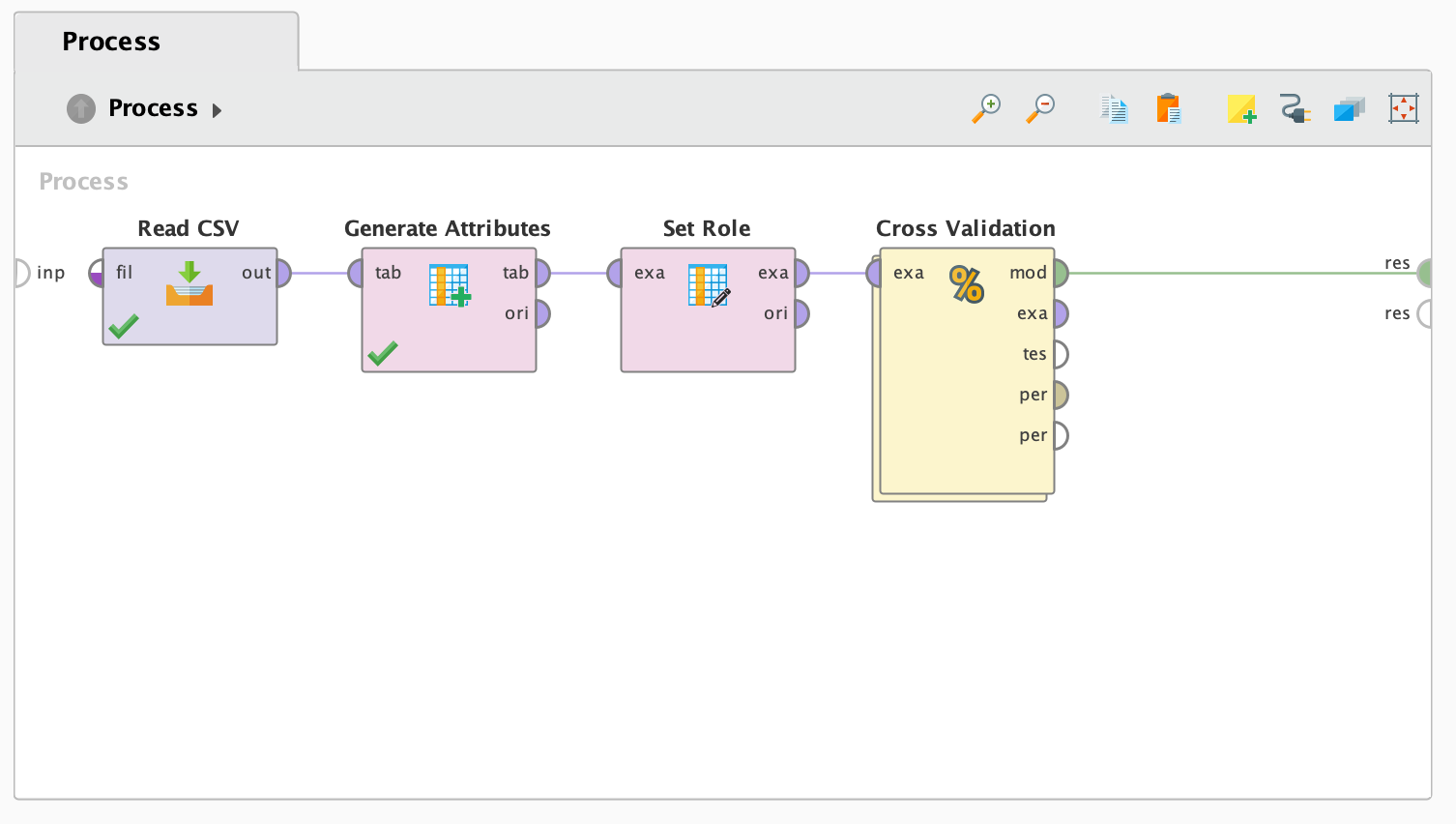
1. Read CSV 오퍼레이터
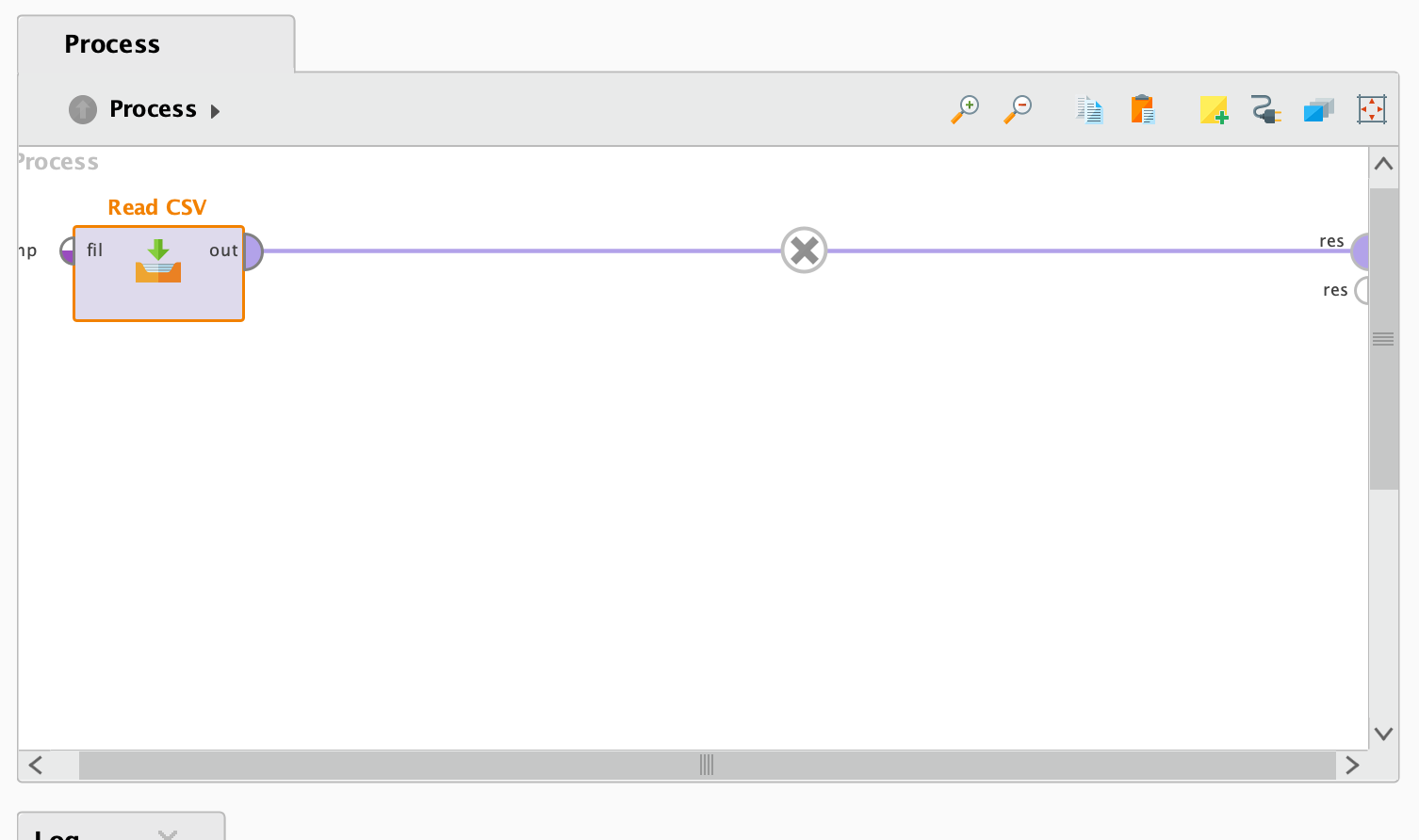
- Read CSV 오퍼레이터의 out 부분을 res 부분과 연결시켜야 합니다.
- 이대로 Run 버튼을 누르시면, 결과는 아래와 같이 나옵니다:
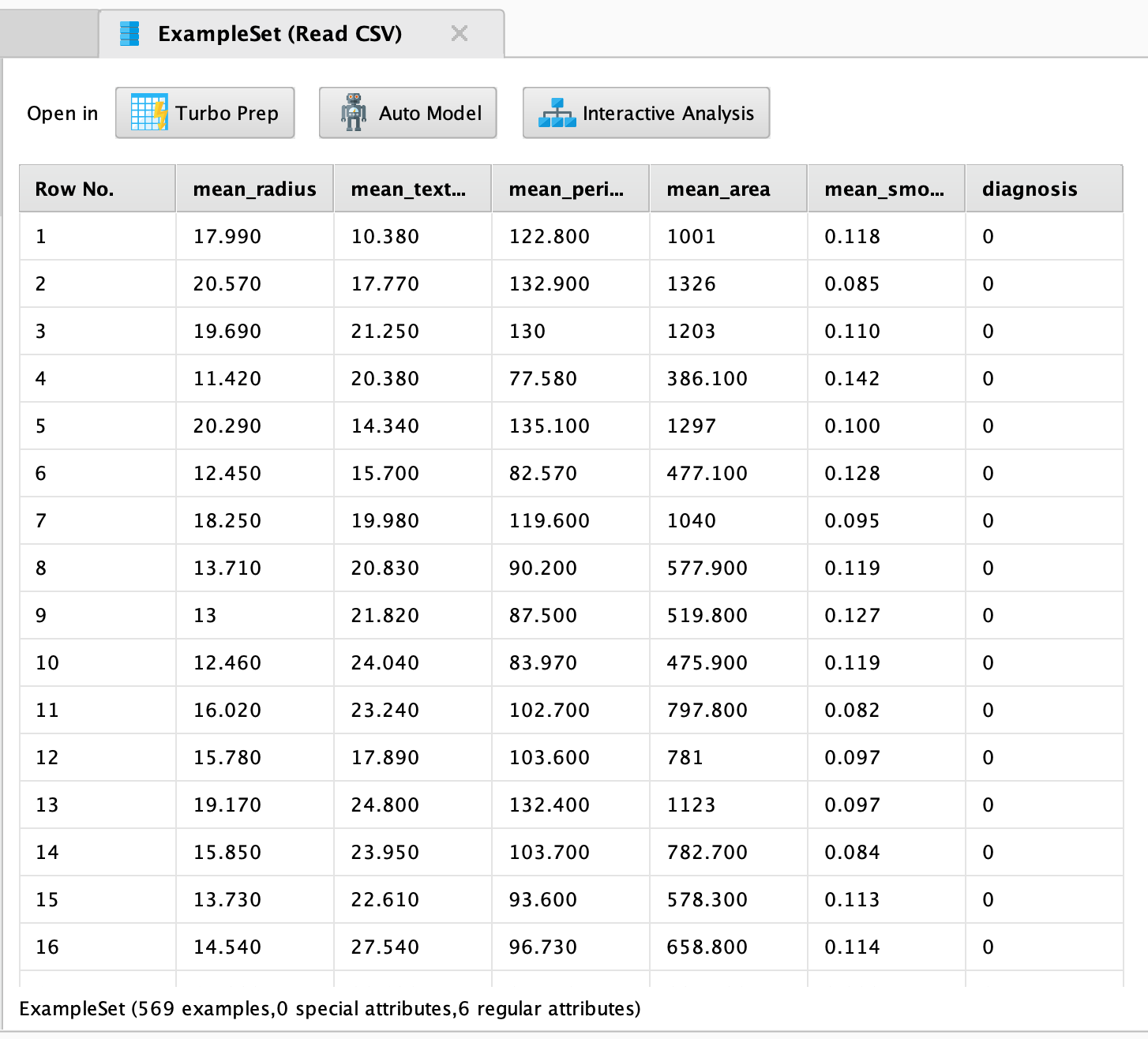
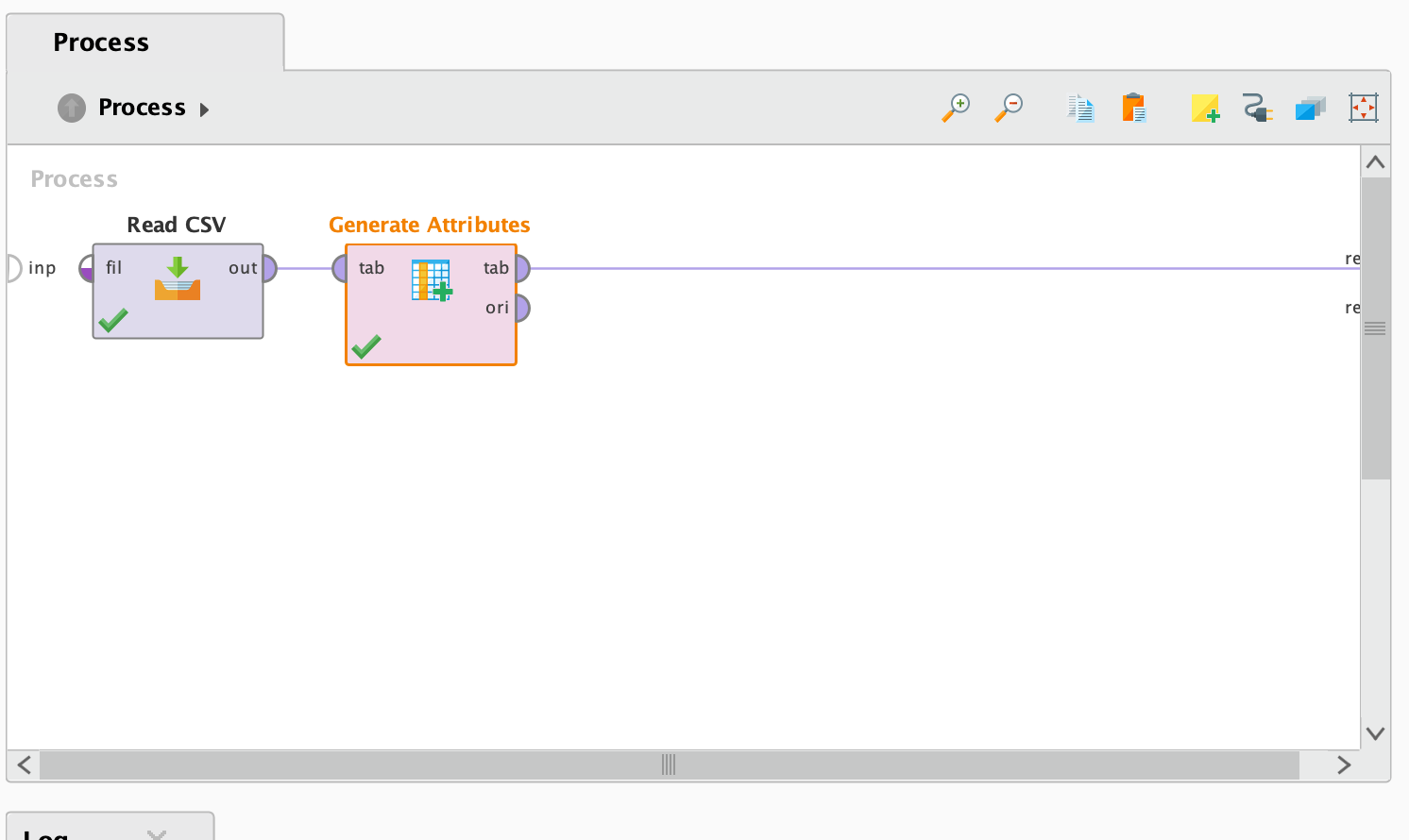
2. Generate Attributes 오퍼레이터
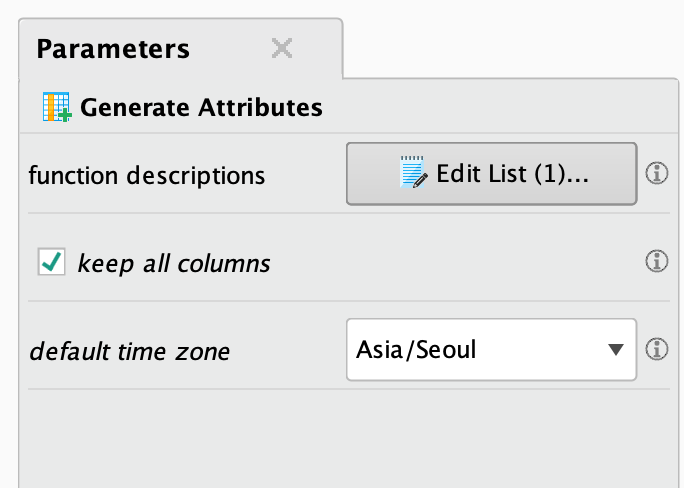
Generate Attributes 오퍼레이터는 속성에 특정 특징을 부여하거나 수정하기 위해 사용됩니다. 여기서 diagnosis 속성은 우리의 타겟 변수로, 일반적으로 1과 0의 이진 값으로 표현됩니다. 이 오퍼레이터를 사용하여 해당 값을 pos와 neg로 라벨링할 것입니다. 이는 LightGBM이 범주형 변수를 필요로 하기 때문입니다. 이를 위해 오퍼레이터의 내부에 다음과 같은 표현식을 작성해야 합니다:
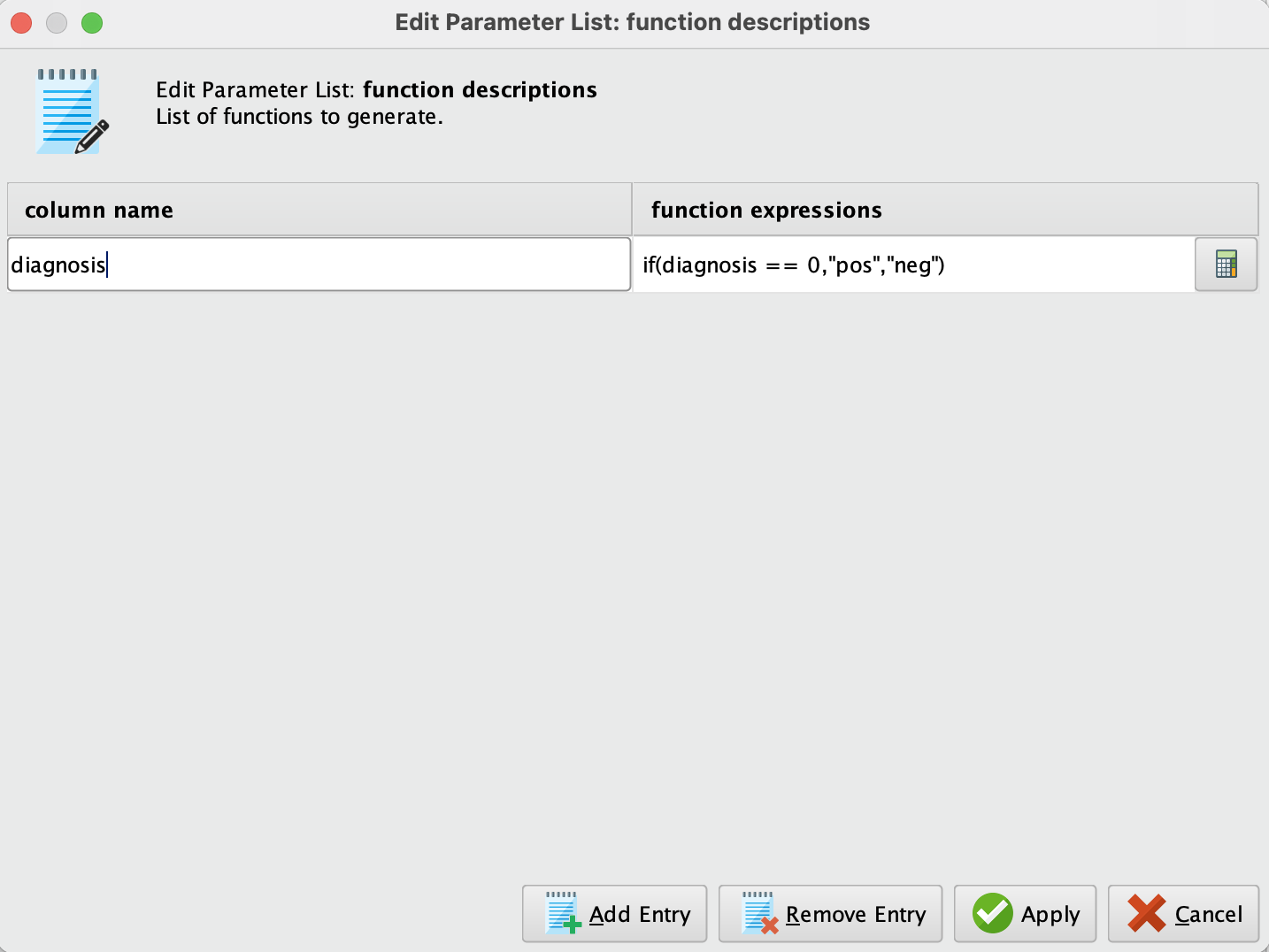
3. Set Role 오퍼레이터
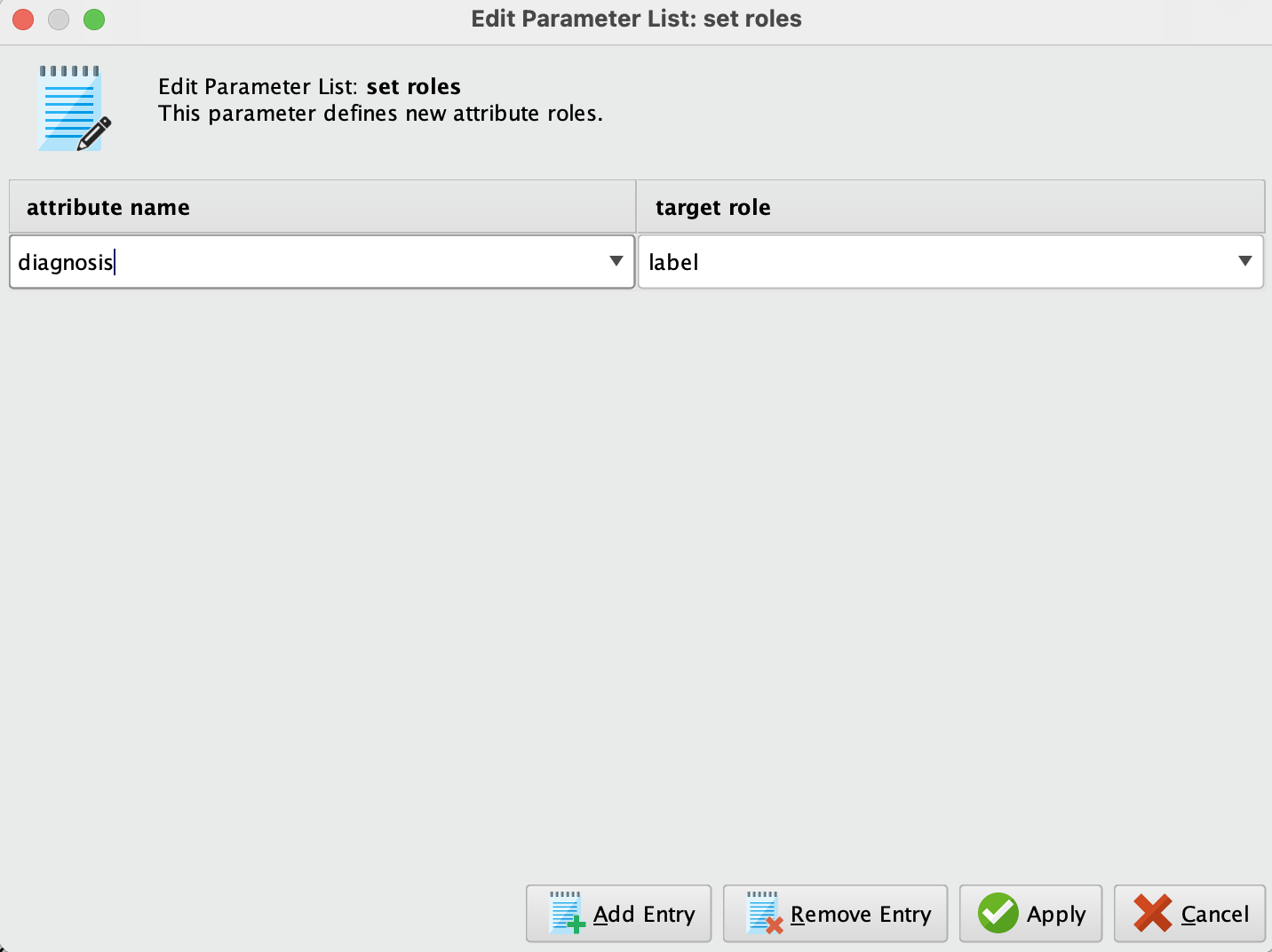
이 단계에서는 Set Role 오퍼레이터를 사용하여 우리의 타겟 변수가 무엇인지 지정할 것입니다. 즉, diagnosis 속성에 "label" 역할을 부여하게 됩니다. 이렇게 하면 모델 학습 과정에서 이 속성이 타겟 변수로 인식되도록 설정됩니다.
4. Cross Validation 오퍼레이터
이제 모델을 생성하고 사용할 준비가 되었고, 데이터셋과 속성을 준비했습니다. 다음으로, Cross Validation 오퍼레이터를 프로세스에 드래그하여 추가합니다. 그런 다음 오퍼레이터를 두 번 클릭하여 설정 화면을 엽니다.
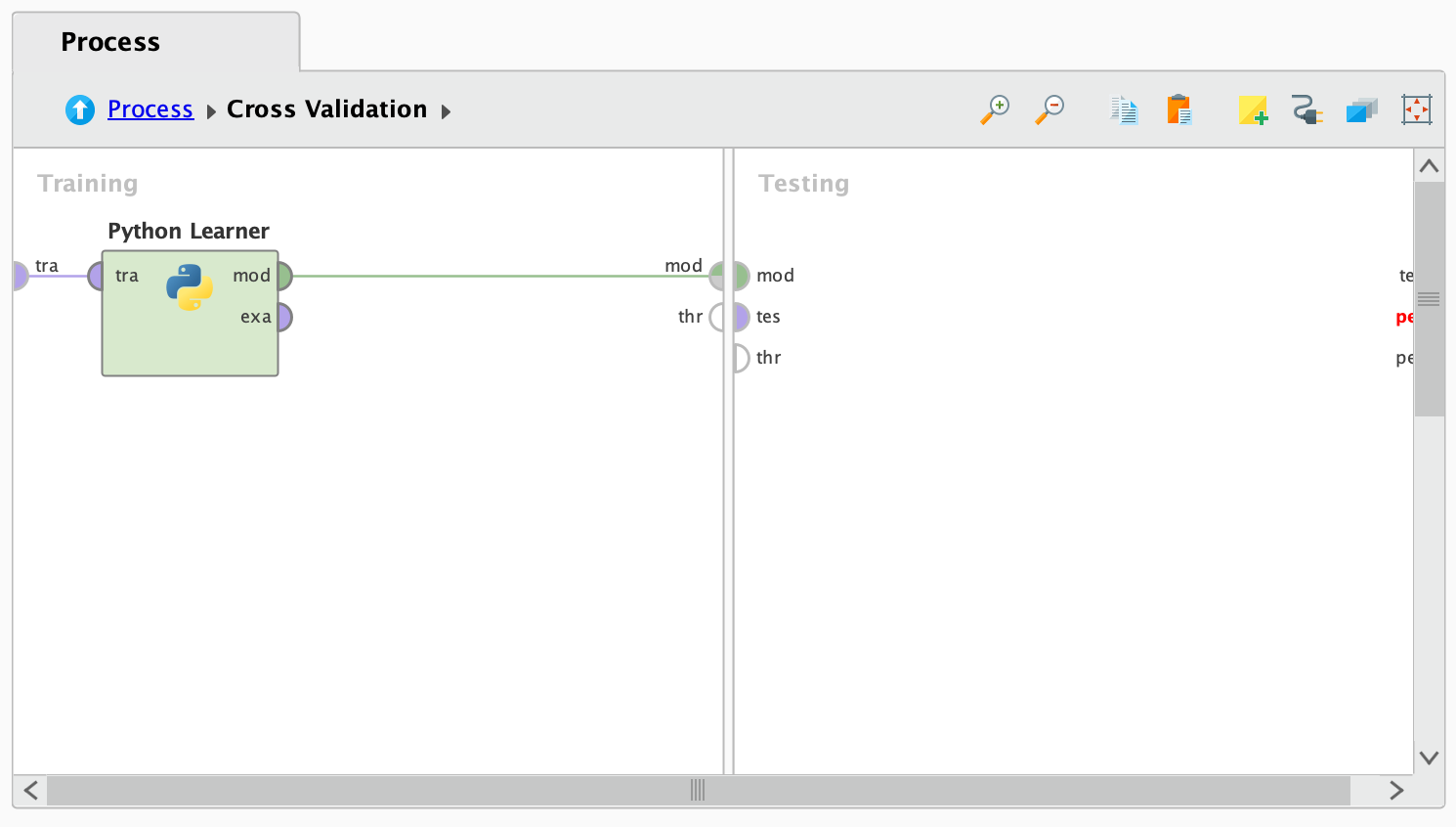
Cross Validation 오퍼레이터의 내부를 살펴보면, 왼쪽과 오른쪽 부분이 각각 training과 testing으로 나뉘어 있는 것을 확인할 수 있습니다. 여기서 training 부분에는 Python Learner 오퍼레이터를 사용하여 LightGBM 알고리즘을 구현할 것입니다. 이를 위해 Cross Validation의 왼쪽 부분에 Python Learner 오퍼레이터를 드래그하여 추가합니다.
- Python Learner 오퍼레이터를 클릭하면 오른쪽에서 Script와 Parameter 섹션을 확인할 수 있습니다. 여기서 먼저 파라미터를 다음과 같이 설정할 것입니다. 이 파라미터들은 LightGBM 알고리즘의 하이퍼파라미터로 사용되며, 사용자가 필요에 따라 UI를 통해 파라미터 튜닝을 할 수 있도록 합니다.
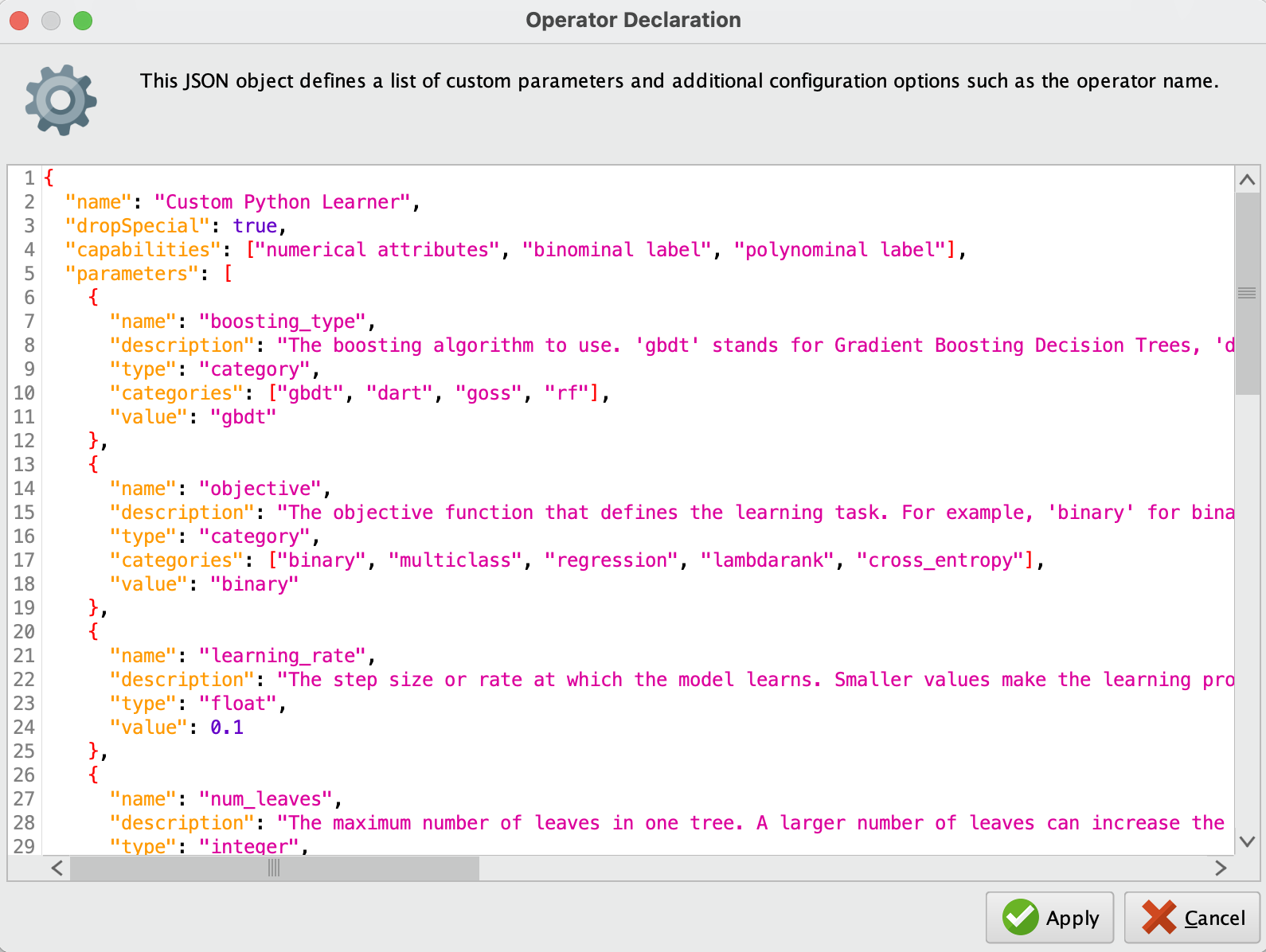
{
"name": "Custom Python Learner",
"dropSpecial": true,
"capabilities": ["numerical attributes", "binominal label", "polynominal label"],
"parameters": [
{
"name": "boosting_type",
"description": "The boosting algorithm to use. 'gbdt' stands for Gradient Boosting Decision Trees, 'dart' uses Dropouts in GBDT, 'goss' is Gradient-based One-Side Sampling, and 'rf' is Random Forest.",
"type": "category",
"categories": ["gbdt", "dart", "goss", "rf"],
"value": "gbdt"
},
{
"name": "objective",
"description": "The objective function that defines the learning task. For example, 'binary' for binary classification, 'multiclass' for multi-class classification, 'regression' for regression tasks, 'lambdarank' for ranking problems, and 'cross_entropy' for cross-entropy-based learning.",
"type": "category",
"categories": ["binary", "multiclass", "regression", "lambdarank", "cross_entropy"],
"value": "binary"
},
{
"name": "learning_rate",
"description": "The step size or rate at which the model learns. Smaller values make the learning process more robust but slower, while larger values may speed up learning but can result in overfitting.",
"type": "float",
"value": 0.1
},
{
"name": "num_leaves",
"description": "The maximum number of leaves in one tree. A larger number of leaves can increase the accuracy but may lead to overfitting.",
"type": "integer",
"value": 31
},
{
"name": "n_estimators",
"description": "The number of boosting iterations or trees to be built in the model.",
"type": "integer",
"value": 100
},
{
"name": "feature_fraction",
"description": "The proportion of features (columns) to be randomly selected for training at each iteration. A smaller fraction can prevent overfitting.",
"type": "float",
"value": 1.0
},
{
"name": "bagging_fraction",
"description": "The proportion of data (rows) to be randomly selected for training at each iteration. Useful to prevent overfitting.",
"type": "float",
"value": 1.0
},
{
"name": "bagging_freq",
"description": "Controls the frequency of bagging. A value of 0 disables bagging, while a higher value specifies the number of iterations after which bagging is performed.",
"type": "integer",
"value": 0
},
{
"name": "max_depth",
"description": "The maximum depth of the trees. A higher value can increase the model's complexity and accuracy, but may cause overfitting. A value of -1 means no limit.",
"type": "integer",
"value": -1
},
{
"name": "min_child_samples",
"description": "The minimum number of samples required in a leaf. Reducing this number may make the model more complex and prone to overfitting.",
"type": "integer",
"value": 20
},
{
"name": "lambda_l1",
"description": "L1 regularization term on weights to reduce overfitting by making the model simpler. Higher values enforce stronger regularization.",
"type": "float",
"value": 0.0
},
{
"name": "lambda_l2",
"description": "L2 regularization term on weights to reduce overfitting. Like L1, but it tends to shrink the weights without making them zero.",
"type": "float",
"value": 0.0
},
{
"name": "min_split_gain",
"description": "The minimum gain required to perform a split. Larger values make the algorithm more conservative, requiring more informative splits.",
"type": "float",
"value": 0.0
}
],
"inputs": [],
"outputs": []
}
- Python Script 안에 모델을 학습(fit)하는 부분을 추가하는 것이 이 오퍼레이터의 주요 구성 요소를 형성합니다.
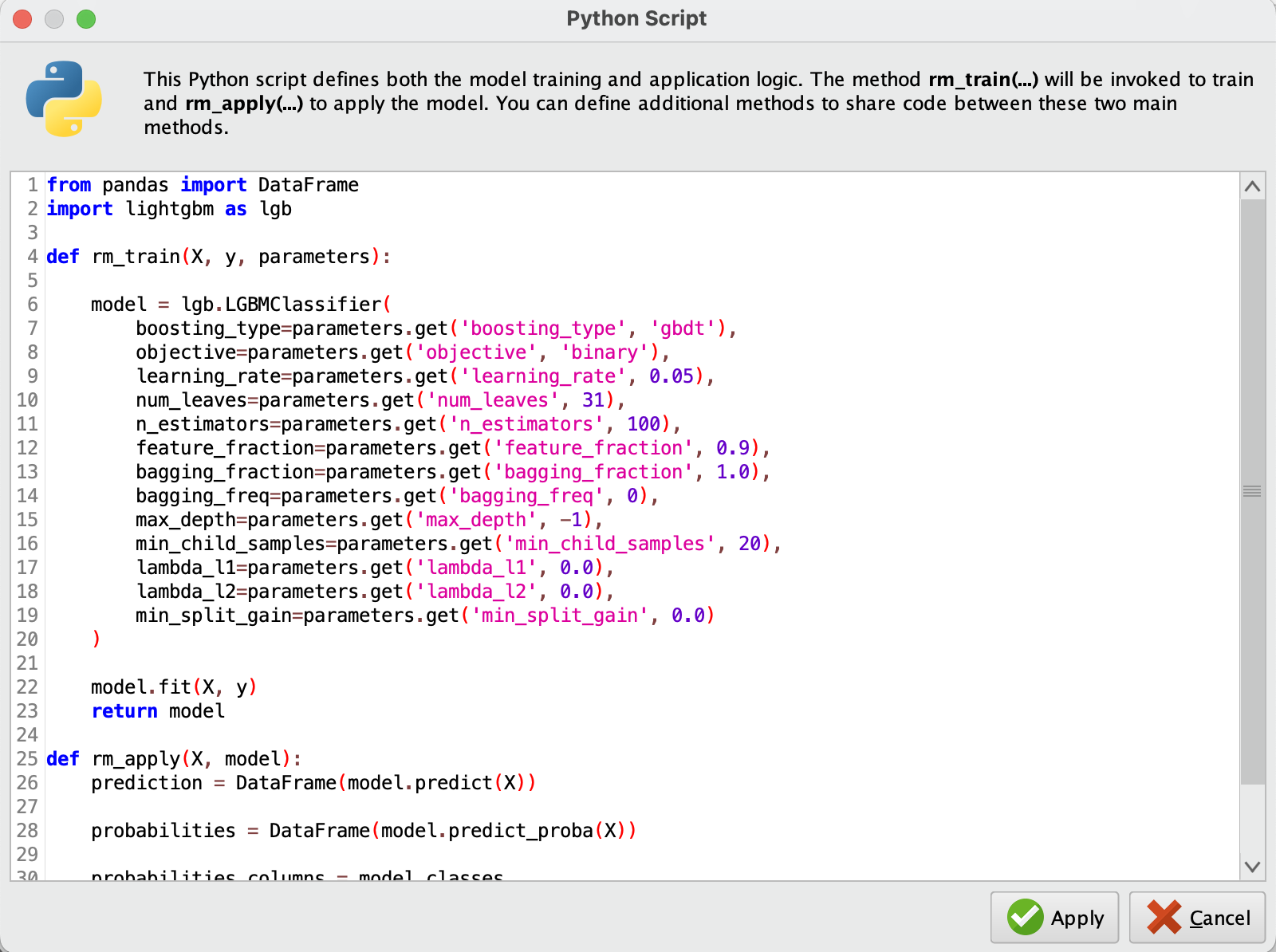
from pandas import DataFrame
import lightgbm as lgb
def rm_train(X, y, parameters):
model = lgb.LGBMClassifier(
boosting_type=parameters.get('boosting_type', 'gbdt'),
objective=parameters.get('objective', 'binary'),
learning_rate=parameters.get('learning_rate', 0.05),
num_leaves=parameters.get('num_leaves', 31),
n_estimators=parameters.get('n_estimators', 100),
feature_fraction=parameters.get('feature_fraction', 0.9),
bagging_fraction=parameters.get('bagging_fraction', 1.0),
bagging_freq=parameters.get('bagging_freq', 0),
max_depth=parameters.get('max_depth', -1),
min_child_samples=parameters.get('min_child_samples', 20),
lambda_l1=parameters.get('lambda_l1', 0.0),
lambda_l2=parameters.get('lambda_l2', 0.0),
min_split_gain=parameters.get('min_split_gain', 0.0)
)
model.fit(X, y)
return model
def rm_apply(X, model):
prediction = DataFrame(model.predict(X))
probabilities = DataFrame(model.predict_proba(X))
probabilities.columns = model.classes_
return prediction, probabilities
- 파라미터 섹션에서 설정한 값들은 Python 스크립트 내에서 다음과 같이 parameters.get 함수를 사용하여 가져올 수 있습니다.
boosting_type=parameters.get('boosting_type', 'gbdt'),
5. Apply Model & Performance(Classification) 오퍼레이터
LightGBM 모델을 만든 후 (Python Learner의 이름을 "LightGBM"으로 변경), "Apply Model" 및 "Performance" 오퍼레이터를 추가합니다. 아래와 같이 포트를 연결합니다.
- LightGBM의 model 포트를 Apply Model의 model 포트에 연결합니다.
- Apply Model의 lab 포트를 Performance의 lab포트에 연결합니다.
- 마지막으로 Performance의 per 포트를 per 포트로 연결합니다.
- 이렇게 연결하면, Training 부분이 구성되어 LightGBM 모델을 적용하고 성능을 평가할 수 있는 준비가 완료됩니다.
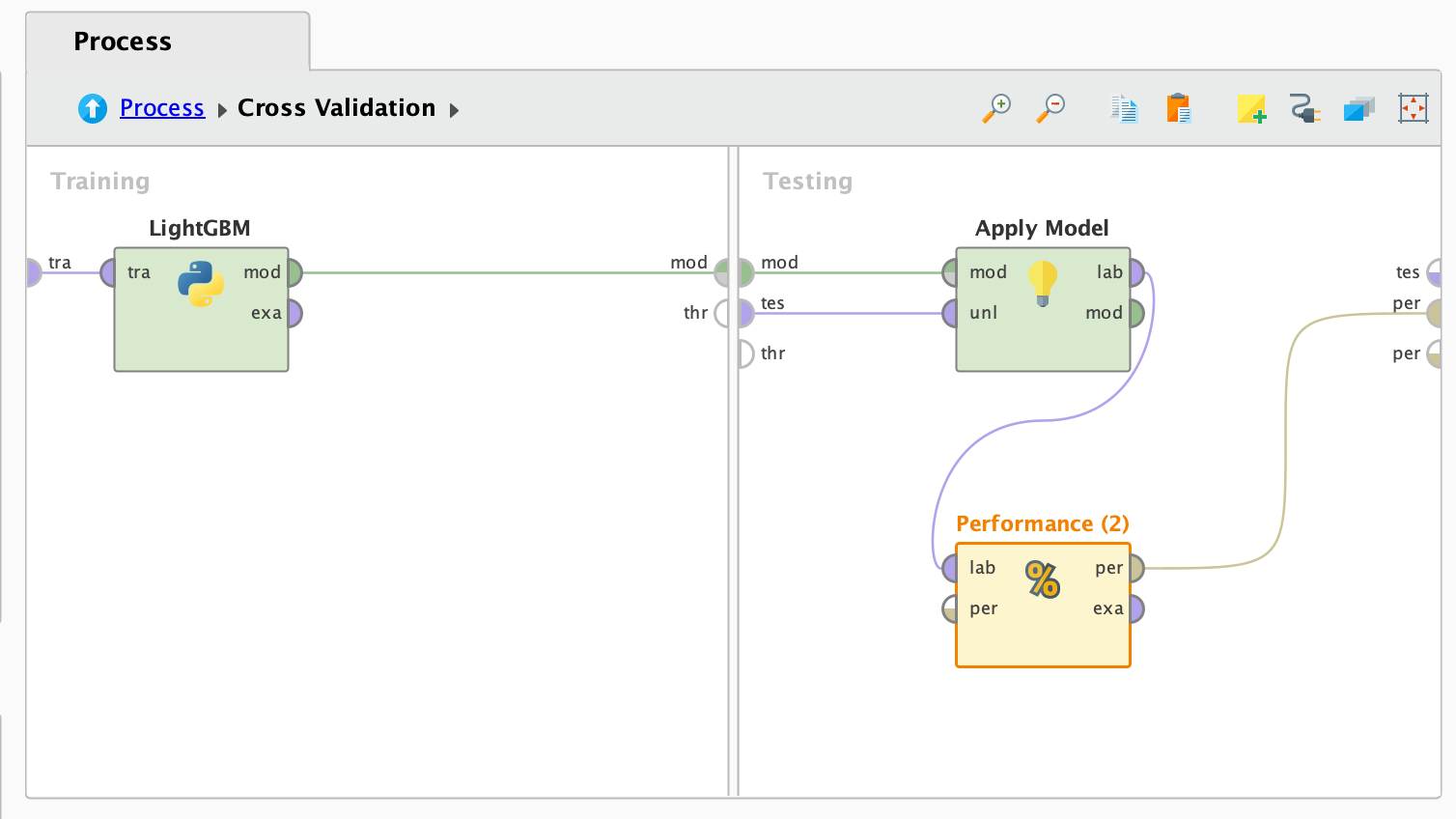
- "Performance"의 오른쪽 창에서 성능 지표를 설정하여 결과에 표시할 수 있습니다.
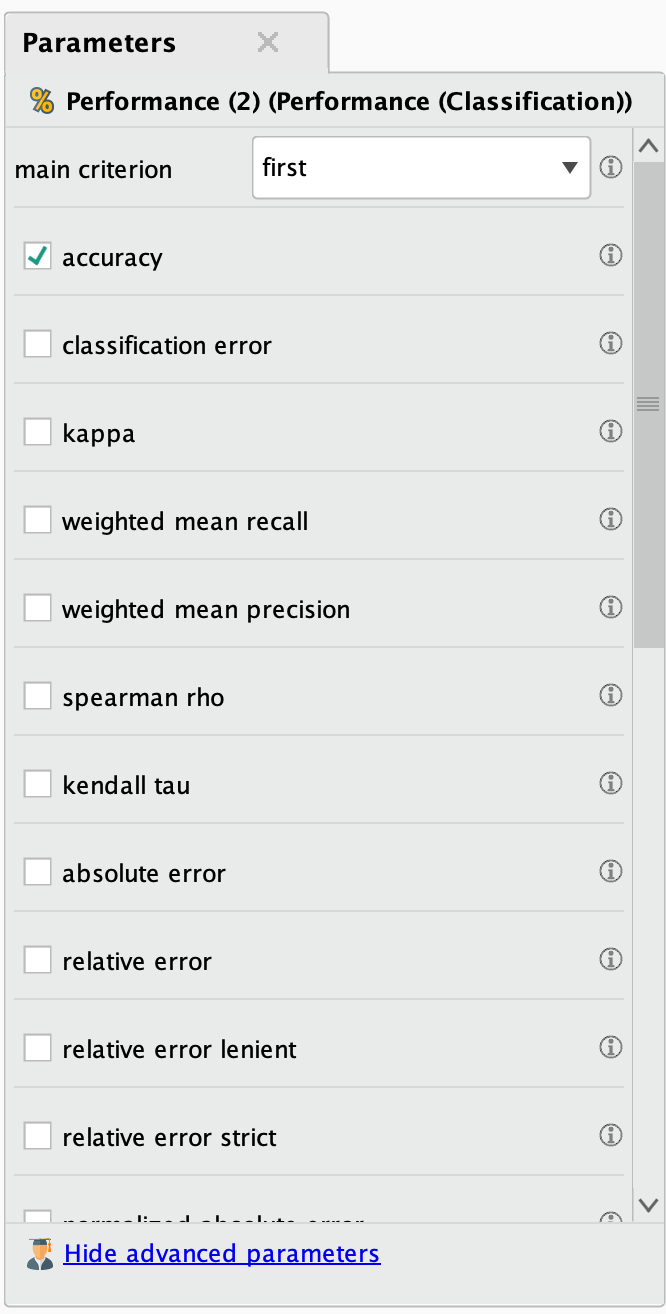
- 마지막으로 Cross Validation의 output을 다음과 같이 연결한 후, 모든 프로세스를 완료하게 됩니다.
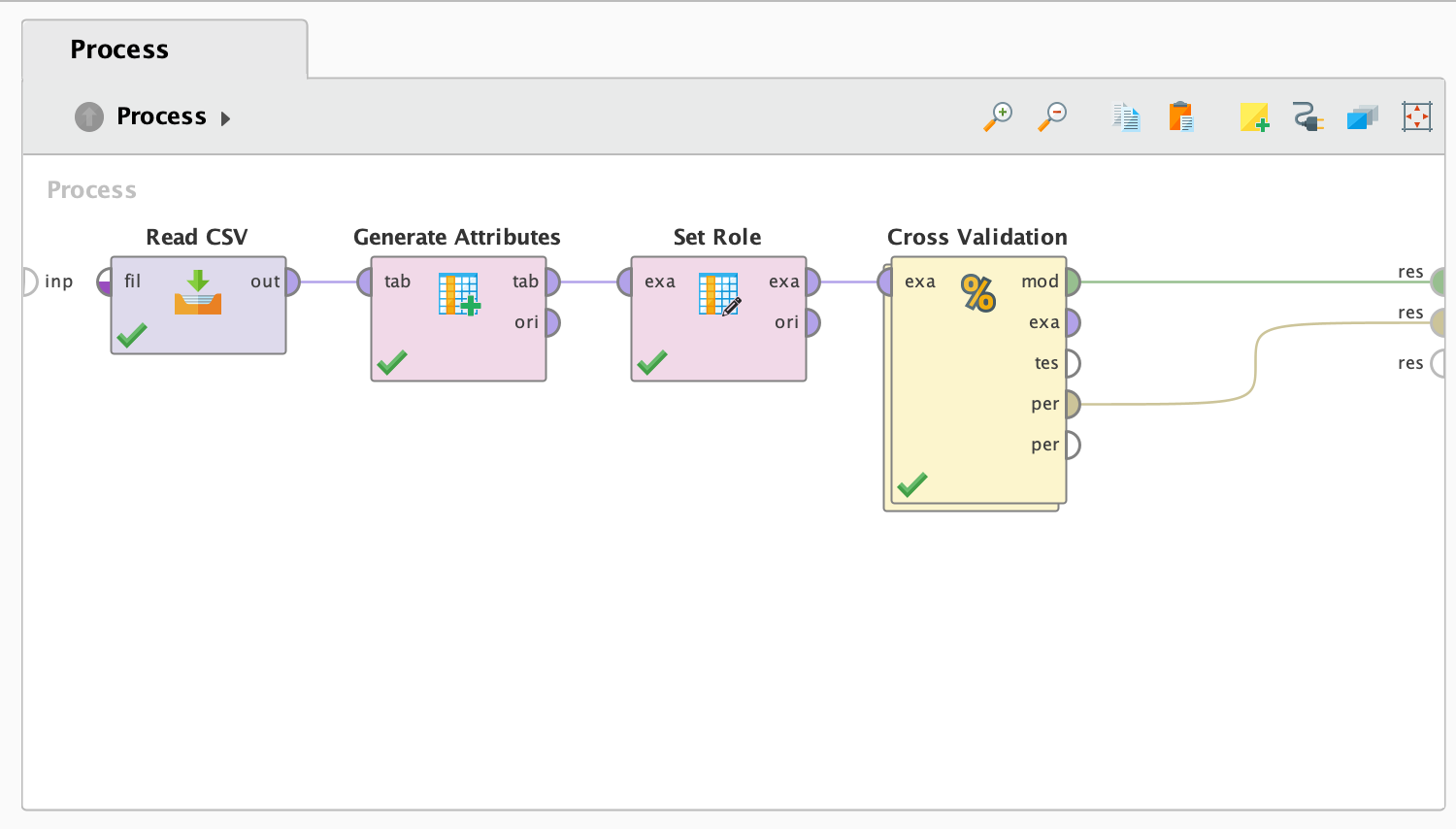
- 프로세스를 실행한 결과, 성능은 다음과 같이 나왔습니다:
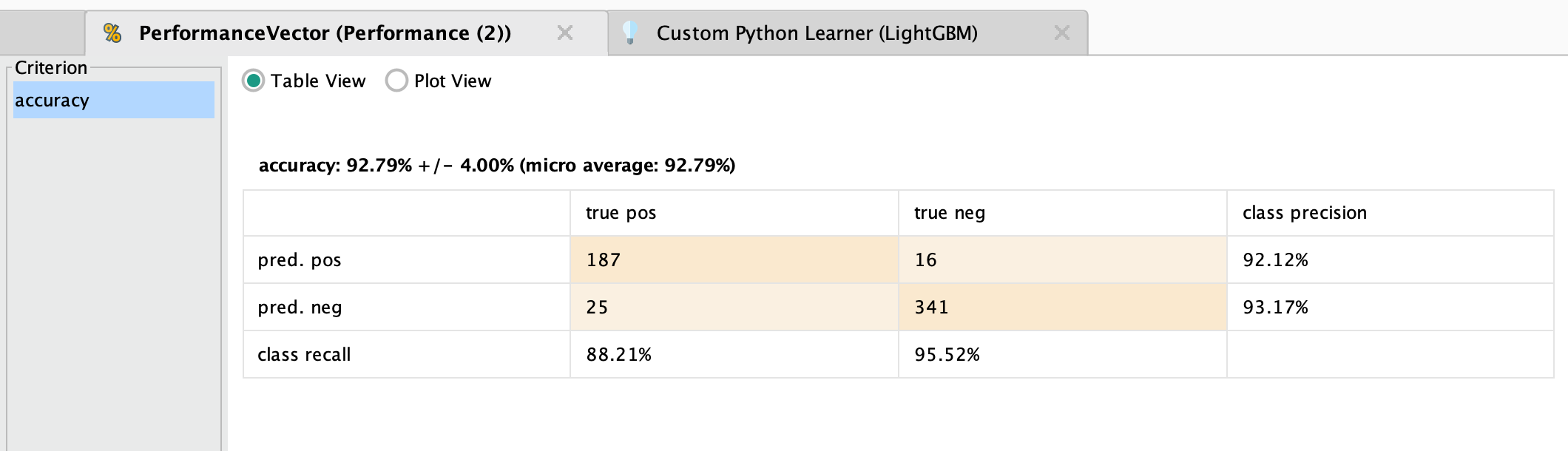
이렇게 Python Learner 오퍼레이터를 사용하여 LightGBM 모델을 만들었습니다. 다음 블로그 포스트에서는 생성한 이 머신러닝 모델을 RapidMiner에 저장하고 오퍼레이터 확장(Extension)을 만드는 방법을 보여드리겠습니다! ☺️
'래피드마이너' 카테고리의 다른 글
| 래피드마이너에서 커스텀 오퍼레이터 저장하는 방법 (6) | 2024.10.09 |
|---|
